-
 Subscribe
Subscribe
- Tweet
Sorry for not posting in a while. Things have been really hectic in my personal and work life so I haven't been able to put as much into newsrdr as I'd like. However, I do have a few bits of good news:

What's next? I think I'm going to focus more on marketing. I've heard that people have achieved good things from press releases, and I'm considering going that route. What do you like about newsrdr vs. other sites?
For a good amount of time, newsrdr has been behaving extremely slowly when accessing certain portions of the interface. In particular, "All Feeds" would take up to 10-20 seconds to download data from the server. As it turns out, MySQL had serious issues performing well with the original database structure. To produce the necessary data from the server, several joins on various tables were needed. Because of these joins, sorting the results required significant time, especially given the size of the AWS resources in use today.
Because of this, some tables were merged together tonight. This required significant code changes in the backend, as well as a couple of hours of downtime to port the current data over to the new tables. If you were using newsrdr while this was happing, my apologies. Hopefully things are much faster now and that the downtime was worth the trouble.
Please let me know via the Contact link above if there are any issues.
Giles Alexander wrote a blog post recently about the downsides of Scala. I figured I'd give an alternate viewpoint, considering a) newsrdr was written in Scala and b) this is my first time using Scala. Note that this is nowhere near comprehensive, since I'm still learning and all.
For a test, I ran a completely clean rebuild of newsrdr from the github repo from my late-2013 13" MacBook Pro:
harry:newsrdr mooneer$ time ./sbt package
Detected sbt version 0.12.3
Using /Users/mooneer/.sbt/0.12.3 as sbt dir, -sbt-dir to override.
[info] Loading project definition from /Users/mooneer/newsrdr/project/project
[info] Loading project definition from /Users/mooneer/newsrdr/project
[info] Set current project to newsrdr (in build file:/Users/mooneer/newsrdr/)
[info] Updating {file:/Users/mooneer/newsrdr/}newsrdr...
[info] Resolving org.slf4j#slf4j-api;1.6.1 ...
[info] Done updating.
[info] Compiling 5 CoffeeScripts to /Users/mooneer/newsrdr/target/scala-2.10/resource_managed/main/webapp/js
[info] Generating /Users/mooneer/newsrdr/target/scala-2.10/resource_managed/main/rebel.xml.
[info] Compiling Templates in Template Directory: /Users/mooneer/newsrdr/src/main/webapp/WEB-INF/templates
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
[info] Compiling 34 Scala sources to /Users/mooneer/newsrdr/target/scala-2.10/classes...
[warn] there were 4 deprecation warning(s); re-run with -deprecation for details
[warn] one warning found
[info] Packaging /Users/mooneer/newsrdr/target/scala-2.10/newsrdr_2.10-0.1.0-SNAPSHOT.war ...
[info] Done packaging.
[success] Total time: 61 s, completed Dec 1, 2013 6:48:29 PM
real 1m10.330s
user 2m36.123s
sys 0m3.797s
harry:newsrdr mooneer$
The part that felt like it took the longest appeared to be the CoffeeScript compilation, not the compilation of the Scala code. Compile times will probably be far less in normal development, though YMMV. Recent versions of sbt can now take advantage of parallelism to improve compile times, making the hit far less than in the past.
This was a big winner for me. For instance, there is already a very good task scheduling library called Quartz written in Java, which includes built-in clustering support. Having to duplicate this effort in Scala would honestly not have been a good use of my time. Some other things (such as fetching using HTTP) were also far easier using Oracle's libraries. It also works the other way--if I ever needed to, I could release a JAR that Java developers can use in their own applications.
There is definitely a Scala way of doing things, much like how there is a Java way of doing things, a C# way of doing things, etc. The advantages and disadvantages of operator overloading are definitely in play in Scala, and basically boils down to the library developer. If someone overloads an operator in an unexpected way, I'm more apt to blame the library developer rather than the language itself. Basically, Scala gives back some of the power that's lost when using Java, and that's a good thing.
Even if we admit that operator overloading is a negative for the language, the language itself still grants far easier entry into functional programming than some of the others out there. For instance, in the past I tried Haskell and kept banging my head against the wall. Some day I'll probably try it again, but for now Scala allows me to get stuff done.
I've found the Scala type system to be extremely flexible. For example, traits effectively act as mixins for classes; the equivalent in Java would be extremely difficult to implement. The other advantage of having types everywhere is that you can do a lot more checking at a static level vs. finding out the hard way that a Content-Length header isn't supposed to be a string. This helps significantly with program correctness.
For me, Scala was perfectly accessible. One does need to define "accessible", though: I have significant programming experience from my day job as well as previous personal projects. I imagine someone who have never developed before would be better off starting with something like Java or Python first. For anyone interested, there was a Scala course on Coursera recently that's highly recommended. Even though the course is done for now, the materials are still up and can be worked through. There's also a tutorial written especially for Java developers (warning: PDF).
Would I write newsrdr in Scala again? Yes. Future projects? Depends on the project.
Just pushed a new change tonight that adds this new piece of UI:
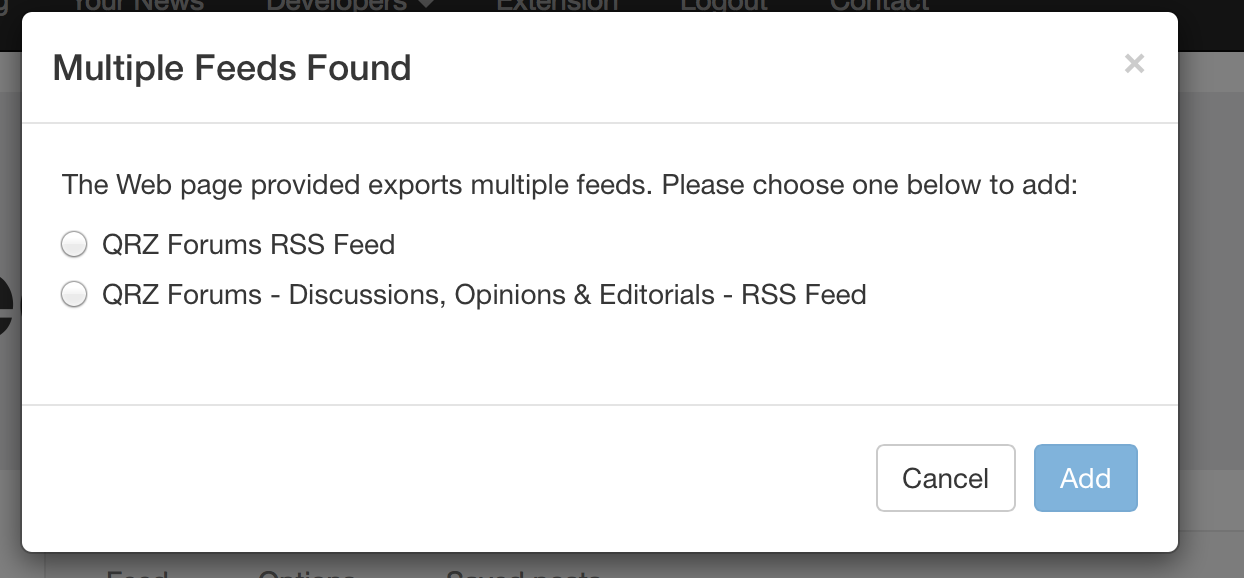
Some background: there is a HTML tag called <link> that Web site operators can add to their pages that directs RSS reader software to the correct feed to use. Websites can have more than one of these, each of them referring to a different RSS or Atom feed. In the past, newsrdr simply chose the first RSS feed found when a user adds a URL to a Web page, which wasn't always the one the user wanted. This feature means that users can now choose the correct feed to add (or even all of them if they wanted).
For more details on what exactly changed in the code, see the commit on Github.
newsrdr now has browser extensions available!
Chrome: https://chrome.google.com/webstore/detail/newsrdrus-checker/bnchcmdgmdfnhelmcfaebjiggnldiedf?hl=en&gl=US
Safari: http://newsrdr.us/extension/safari/newsrdr-checker.safariextz
Firefox: https://addons.mozilla.org/en-US/firefox/addon/newsrdrus-checker/
Basically, as long as you're logged into newsrdr, the extension will show a button in your browser's toolbar with the number of unread posts. It also provides an easy way to log into newsrdr: simply click on the button.
Let me know here if you run into any issues.
Remember that sneak peak I showed earlier today? The initial version is now live.
Basically, this allows you to follow Web sites that do not export RSS or Atom feeds. Of course, newsrdr does best when it has one of those types of feeds to work with, but this gives users another option for following their favorite Web sites.
This feature is still in beta, so please file bug reports (using the Contact link above) as needed. Leave a comment below if you have any questions.
As you may know, newsrdr is a Web application that is designed to stay open in a browser tab in the background for potentially long periods of time. This means that it needs to manage memory usage carefully to ensure the best user experience. Much like most Web sites today, newsrdr uses JavaScript to handle UI and other front-end tasks, which has garbage collection.
I personally use newsrdr on both a 2010 MacBook Pro (running Safari) and on Chrome in Windows 7 to follow various tech blogs. Inevitably, Safari would always slow down on the Mac until I either restarted it or it reloaded all of my tabs. One time I had to do this and decided to check Activity Monitor first. I saw something like this:

"But I thought JavaScript had garbage collection," I said. Time to break out the tools and find out what was going on.
Unfortunately, Safari does not have readily accessible memory profiling functionality. According to a post on Stack Overflow, instrumenting JavaScript involves running Instruments (an application that comes with Xcode). I started a new instance of Safari with just newsrdr open and played around a bit. Instruments was of little help, though, as it did not give me any sort of output. I could have played with it some more, but there was an easier alternative: Google Chrome.
See, Google Chrome has a full-featured JavaScript and DOM (Document Object Model) debugger. It also uses WebKit, so it's an almost perfect substitute for Safari. (I say "almost" because there was still a chance that I couldn't duplicate the issue due to minor differences in the code between the two browsers.) Anyway, choosing Tools->Developer Tools from the main Chrome menu brings up this awesome window:

Profiles sounds promising. Clicking on that brings up a tab with several options, including "Record Heap Allocations" and "Take Heap Snapshot". I took an initial heap snapshot, played around with the site a bit (basically: add a couple of feeds and go to Home), and took another snapshot.
Chrome has an option to compare the current snapshot with any previous snapshot, and here's what I discovered:

Of course, there should be no references to any <video> tags anywhere, since the site removes all post HTML from the DOM upon changing pages. Further investigation revealed that the feeds I had added contained embedded YouTube videos. Now I know why there are <video> tags, but why aren't they getting cleaned up?
When someone embeds a YouTube video onto a Web page, the page contains an <iframe> tag that loads the video from YouTube's Web site. An <iframe> is a HTML tag that allows a developer to load another Web page inside the existing one. This allows the developer to do cool things. Like, say, loading embedded content based on the user's browser. When an <iframe> gets parsed by the browser, a new entry gets added to the window.frames array. This reference sticks around even after the <iframe> gets removed from the DOM due to it being part of the window and not the document. There's our reference to the video right there.
Fortunately, fixing this is simple. While we can't necessarily remove the <iframe> from there, we can remove the code and DOM that YouTube created by navigating to about:blank (which produces a blank HTML page). In CoffeeScript:
_leakCleanup: () ->
# We need to navigate all iframes inside the article to about:blank first.
# Failure to do so results in memory leaks.
frameList = this.$('iframe')
for i in frameList
i.contentWindow.location.href = "about:blank"
frameList.remove()
After adding this code and running the same test again, I found that the amount of heap used between the two snapshots was pretty much constant. Success!  I immediately checked this change into the tree.
I immediately checked this change into the tree.
In conclusion, memory leaks are fairly easy to find with the right tools. There's no excuse not to do at least a cursory check before releasing a new project or a change to an existing one. Hopefully this helped some people with their own Web projects.
Feel free to leave feedback below, or use the Contact link above if you run into other issues using newsrdr.
Hi everyone! I figured there needed to be a news type section here, so I went ahead and wrote a quick blog implementation. (BTW, you can look at the source code at github )
Anyway, I have some interesting posts coming up regarding the architecture of this site, so stay tuned!
